
Positioning is private. Messaging is public. That distinction, simple as it sounds, is where a remarkable number of product marketing efforts come unstuck. You can spend weeks refining your positioning using April Dunford's five-component framework, validating every assumption against customer perception, and emerging with a positioning document that is genuinely excellent. And then someone has to write the landing page. Someone has to compose the email subject line. Someone has to distil months of strategic thinking into fourteen words on a billboard. That is where messaging begins, and it is where most of the value leaks out.
The problem is not a lack of effort. The problem is a lack of feedback. Product marketers write messaging variants, circulate them internally, receive conflicting opinions from stakeholders who are not the target customer, pick the version the highest-paid person in the room prefers, and ship it. The market then provides its verdict in the form of conversion rates, open rates, and sales cycle lengths, but by the time you have enough data to draw conclusions, weeks have passed and the launch window is closing.
There is a better way. This article explains how to test product messaging in real time using Ditto, a synthetic market research platform with over 300,000 AI personas, and Claude Code, Anthropic's agentic development environment. The workflow tests three messaging variants against target personas, analyses which lands and why, refines the losers based on persona feedback, and re-tests the improved versions. Two complete rounds of message testing in about an hour. The same process through traditional tools like Wynter takes days per round and costs hundreds of dollars per test.
Why Messaging Testing Is the Most Neglected PMM Skill
Consider what a Product Marketing Alliance survey found: ninety-one percent of product marketers identify positioning and messaging as their core responsibility. Eighty percent say creating sales collateral is a key part of their role. Yet when you ask how many systematically test their messaging before launching it, the number drops precipitously. Most teams test landing page copy through A/B tests after launch, using real traffic and real conversions as the feedback mechanism. This is the equivalent of testing your parachute by jumping out of the plane.
The reason is straightforward: traditional message testing is slow and expensive. Arranging a panel of target buyers, presenting messaging variants, collecting structured feedback, and analysing responses takes one to two weeks per round through specialist platforms, and longer if you are doing it manually through customer interviews. When you are launching a product next Thursday, two weeks is a luxury you do not have.
This creates a peculiar situation. Positioning, which is internal and strategic, gets rigorous validation. Messaging, which is external and is the thing that actually touches customers, gets a gut check and a Slack poll. The discipline that would benefit most from rapid testing receives the least.
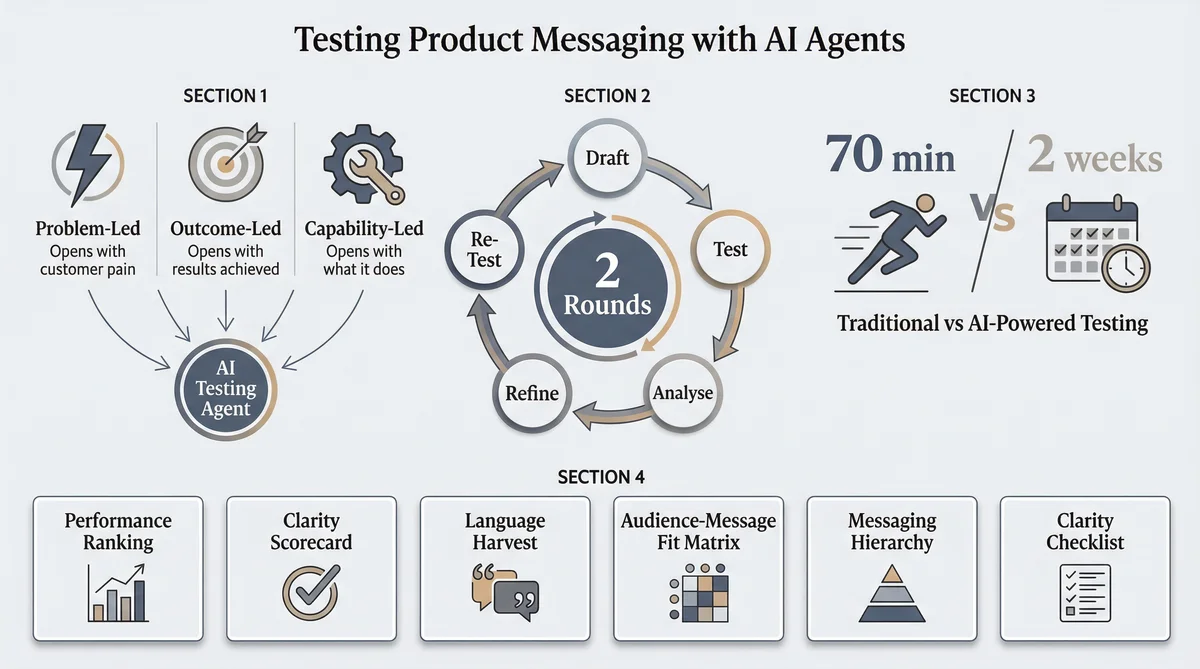
Three Framings, One Product: The A/B/C Approach
Before testing messaging, you need variants worth testing. The messaging hierarchy sits beneath positioning in the PMM stack: your positioning defines what to say, whilst your messaging determines how to say it. The same positioning can produce radically different messaging depending on which framing you lead with.
The three canonical framings are:
Problem-led messaging opens with the pain the customer is experiencing. "Tired of spending $50K on research that takes three months?" It works when the problem is universally felt and emotionally resonant. It fails when the audience does not recognise the problem, or when the problem is too abstract to generate urgency.
Outcome-led messaging opens with the result the customer will achieve. "Get validated customer insights in thirty minutes." It works when the outcome is specific, measurable, and desirable. It fails when the audience is sceptical about the claim, or when the outcome sounds too good to be true without supporting evidence.
Capability-led messaging opens with what the product does. "AI-powered synthetic research with 300,000 personas across fifteen countries." It works when the capability itself is the differentiator and the audience is sophisticated enough to infer the benefit. It fails when the audience does not care about the how, only the what.
Most product marketers have a strong intuition about which framing will perform best for their audience. Most product marketers are also wrong a surprising percentage of the time. The value of testing is not confirming what you already believe. It is discovering what you did not expect.
The Seven-Question Message Testing Study
This study design tests three messaging variants against the same persona group. Each question is designed to extract a specific dimension of message performance. Claude Code customises the questions with your actual messaging variants and runs the study through Ditto's API.
Question 1 (Comprehension and Relevance): "Read this message: '[Message A, problem-led]'. In your own words, what is this company offering? Who is it for? Would you want to learn more?"
This is the baseline. If personas cannot accurately describe what you are offering after reading your message, the message has failed before anything else matters. The "who is it for" sub-question reveals whether your targeting is communicated clearly. The "learn more" sub-question measures intent.
Question 2 (Comparative Preference): "Now read this: '[Message B, outcome-led]'. How does this compare to the first? Which feels more relevant to your situation?"
Sequential comparison forces a preference. Personas who thought Message A was "fine" often become more specific when they have something to compare it against. "The first one felt generic. This one speaks directly to my problem." The reasons they give for preferring one over the other are more valuable than the preference itself.
Question 3 (Action Driver Identification): "One more: '[Message C, capability-led]'. Of the three, which would make you most likely to click, sign up, or reach out? Why?"
This is the money question. Preference and action intent are not the same thing. A persona might find Message B the most compelling intellectually but still say Message A would make them click, because the problem resonance is stronger than the outcome appeal. The "why" is essential: it tells you what mechanism drives the action.
Question 4 (Clarity Gaps): "What is unclear or confusing about any of these messages? What questions do they leave unanswered?"
Clarity is not a binary state. A message can be understood and still leave critical questions unanswered. "I get what they do, but I have no idea what it costs." "I understand the claim, but I do not believe it without evidence." These gaps tell you exactly what supporting content, proof points, or follow-up messaging needs to accompany the primary message.
Question 5 (Expectation Alignment): "If you saw the winning message on a website, what would you expect to find when you clicked through?"
This tests message-to-experience alignment. If your message sets an expectation that your landing page does not fulfil, you will see high click-through rates followed by high bounce rates. Personas tell you what they expect, and you can verify that your product experience matches.
Question 6 (Language and Memorability): "What one word or phrase from these messages stuck with you most? What fell completely flat?"
This is the language harvest. The words that stick are the words you should use more. The phrases that fell flat are the ones you should eliminate. Across ten personas, patterns emerge quickly. If seven out of ten remember the same phrase, that phrase has earned its place in your messaging hierarchy. If a phrase that you thought was clever gets cited as "fell flat" by multiple personas, kill it immediately.
Question 7 (Problem Urgency Validation): "Thinking about your actual work or life, which of these problems feels most urgent to you right now? Why?"
This grounds the messaging exercise in reality. The problem your messaging addresses and the problem your audience actually feels urgency about may not be the same problem. When they diverge, you have a messaging-market fit issue that no amount of wordsmithing will solve. This question surfaces that misalignment before you ship.
The Iterative Loop: Test, Refine, Re-Test
A single round of message testing produces useful data. Two rounds produce messaging you can be genuinely confident in. This is where the combination of Ditto and Claude Code becomes difficult to replicate through traditional methods.
The iterative loop works as follows:
Round 1 (30 minutes). Claude Code drafts three messaging variants based on your positioning. Ditto tests them against ten personas using the seven questions above. Claude Code analyses the responses and identifies: which variant won, why the others lost, which specific phrases resonated, which fell flat, what gaps remain.
Refinement (10 minutes). Claude Code rewrites the two losing variants, incorporating the language that worked from the winner, addressing the clarity gaps personas identified, and adjusting the framing based on which problems personas said felt most urgent. The winning variant may also receive minor refinements based on the expectation alignment and clarity feedback.
Round 2 (30 minutes). The three refined variants are tested against a fresh group of ten personas. Fresh personas are essential: you need to confirm that the improvements work on people who have not been primed by the Round 1 messages. If the same variant wins in both rounds, and the persona feedback on the revised losers shows improvement, you have convergence.
The total elapsed time is approximately seventy minutes. The output is a primary message backed by two rounds of qualitative testing, a set of supporting messages that have been refined based on customer language, a clarity checklist of questions your messaging must address, and a language harvest of words and phrases that demonstrably resonate with your target audience.
To put this in perspective: Wynter, which is excellent for B2B message testing, typically returns results in twenty-four to forty-eight hours per round. Two rounds would take four to six days. Qualtrics surveys can take longer. Customer interviews, the gold standard, take weeks to arrange. The Ditto and Claude Code workflow is not faster because it is less thorough. It is faster because the research panel is always available and the analysis is automated.
What Claude Code Produces from a Message Test
A completed message testing study produces raw data: seventy qualitative responses across seven questions from ten personas. Claude Code transforms this into six structured deliverables:
Message Performance Ranking. Which variant won, by how much, and the specific reasons personas cited. Not just "Message B won" but "Message B won because the outcome framing resolved scepticism that the problem framing triggered."
Clarity Scorecard. For each variant: was it understood correctly, was it misinterpreted, what questions did it leave unanswered? Misinterpretation is worse than confusion, because the reader thinks they understand but has the wrong impression.
Language Harvest. Words and phrases that stuck, organised by positive resonance ("keep these") and negative resonance ("kill these"). The language your customers naturally use when describing your value proposition is always more effective than the language your marketing team invented.
Audience-Message Fit Matrix. If personas with different demographics or psychographic profiles responded differently, this matrix maps which message works for which persona type. One message may win overall but lose with your most valuable segment.
Recommended Messaging Hierarchy. A primary message, three to four supporting pillars, and proof points, following the standard messaging hierarchy structure but populated with tested, validated language.
Clarity Checklist. The specific questions personas needed answered. "What does it cost?" "Is there a free trial?" "Who else uses this?" "How long does implementation take?" These become the mandatory content elements for any asset that carries this messaging.
All six deliverables are generated from a single study. They feed directly into website copy, email campaigns, sales pitch decks, ad creative, and product onboarding sequences. The language harvest alone is worth the exercise: instead of guessing which words will resonate, you know.
Advanced: Cross-Segment Message Testing
The basic workflow tests one set of messages against one audience. The advanced version tests the same messages against multiple audiences simultaneously.
Claude Code orchestrates three parallel Ditto studies:
Group 1: SMB decision-makers (age 28 to 40, employed)
Group 2: Enterprise evaluators (age 35 to 55, employed)
Group 3: Technical buyers (filtered by education: bachelor's degree and above)
Same three messages. Same seven questions. Three different audiences. The result is an audience-message fit matrix that reveals, with specificity, which message works for which buyer. The problem-led framing might dominate with SMB buyers who feel the pain acutely, whilst the capability-led framing wins with technical evaluators who want to understand the mechanism. The outcome-led framing might work everywhere, or it might work nowhere.
This has direct implications for go-to-market strategy. If your SMB motion is product-led growth and your enterprise motion is sales-led, the messaging for each channel should reflect what resonates with each segment. One primary message on your website, yes. But the email sequences, the sales scripts, the ad targeting, and the in-product onboarding can each use the variant that tested strongest with the relevant audience.
Where Messaging Testing Fits in the PMM Stack
Messaging is not the starting point. It is the translation layer between positioning and the market. The sequence matters:
Positioning validation determines what to say: your competitive alternatives, unique attributes, value proposition, target customers, and market category.
Message testing determines how to say it: which framing resonates, which words stick, which claims are believed.
Competitive intelligence determines what to say about the competition: landmine questions, quick dismisses, and win themes that inform competitive messaging.
Sales enablement takes the tested messaging and packages it for the sales team: pitch decks, email templates, and demo scripts in language that has been validated against target buyers.
Each layer builds on the previous one. Testing messages before positioning is validated wastes effort on the wrong messages. Testing messages without competitive context misses the objections your sales team will face. The sequence is cumulative: positioning provides the raw material, messaging testing refines the expression, competitive intelligence adds the defensive layer, and sales enablement distributes the result.
With Ditto and Claude Code, the entire sequence from positioning validation through tested messaging can be completed in a single day. That is not an exaggeration. It is arithmetic: thirty minutes for positioning validation, seventy minutes for two rounds of message testing, forty-five minutes for a competitive perception study. Under three hours for the strategic foundation that most product marketing teams spend a quarter building.
Limitations and the Honest Caveat
Synthetic message testing tells you how a representative sample of your target audience says they would respond to your messaging. It does not tell you how they will actually respond when encountering it in the wild, with all the noise, distraction, and contextual baggage of real-world exposure. The correlation between stated preference and actual behaviour is strong, validated at ninety-five percent by EY Americas and in studies at Harvard, Cambridge, and Oxford, but it is not perfect.
The recommended approach is sequential: use Ditto message testing as the fast first pass to narrow three variants down to one, then validate the winner with real-world A/B testing on your actual traffic. The synthetic testing eliminates the obvious losers and refines the remaining messages before you spend real impressions on them. Think of it as a qualifying round: you still run the final, but with better runners.
Additionally, messaging context matters. The same message may perform differently on a landing page (where the visitor has intent), in a cold email (where attention is scarce), and in a sales deck (where a human is providing context). Ditto studies test the message in isolation. Real-world performance depends on the channel, the surrounding content, and the moment in the buyer's journey. Use the Ditto results to identify your strongest core message, then adapt it for each channel with that channel's constraints in mind.
Getting Started
If you are launching a product, repositioning an existing one, or simply tired of the Slack poll approach to messaging decisions, this workflow replaces intuition with data. Write three messaging variants. Test them. Refine the losers. Test again. Ship with confidence.
Ditto provides the always-available research panel. Claude Code handles the orchestration: drafting variants, designing the study, running it through Ditto's API, analysing seventy qualitative responses, and producing the six deliverables listed above. The first round takes thirty minutes. The second takes the same. The result is messaging you can defend with evidence rather than opinion.
Positioning is private. Messaging is public. It deserves at least as much rigour as what it translates.
This is the fourth article in a series on using AI agents for product marketing. The first, Using Ditto and Claude Code for Product Marketing, provides a high-level overview. The second, How to Validate Product Positioning with AI Agents, covers positioning validation using April Dunford's framework. The third, Competitive Intelligence with AI Agents, covers competitive battlecard generation. Future articles will address pricing research, customer segmentation, and the research-to-publication content engine.