
Here is a fact that should unsettle every product marketer who has ever spent a quarter refining a positioning document: your positioning is invisible. Customers never see it. What they see is messaging. The tagline on your homepage, the subject line in the nurture email, the three bullet points beneath the pricing tier, the sentence a sales rep uses when a prospect asks "so what do you actually do?" Positioning is the strategy. Messaging is the execution. And the gap between the two is where most product marketing quietly falls apart.
April Dunford put it sharply in Obviously Awesome: positioning defines your competitive context, your unique value, and your best-fit customer. It answers the question "what are we, and for whom?" But once you have answered that question, an equally important and substantially harder one follows: how do you say it? The same positioning can produce radically different messaging. And the difference between the version that resonates and the version that falls flat is not obvious in a conference room. It is obvious only to customers.
Most product marketing teams validate positioning with genuine rigour. They test it against competitors, pressure-test with sales, refine through customer interviews. Then they hand the positioning document to a copywriter and approve the messaging by consensus in a Google Doc. The positioning was data-driven. The messaging was vibes.
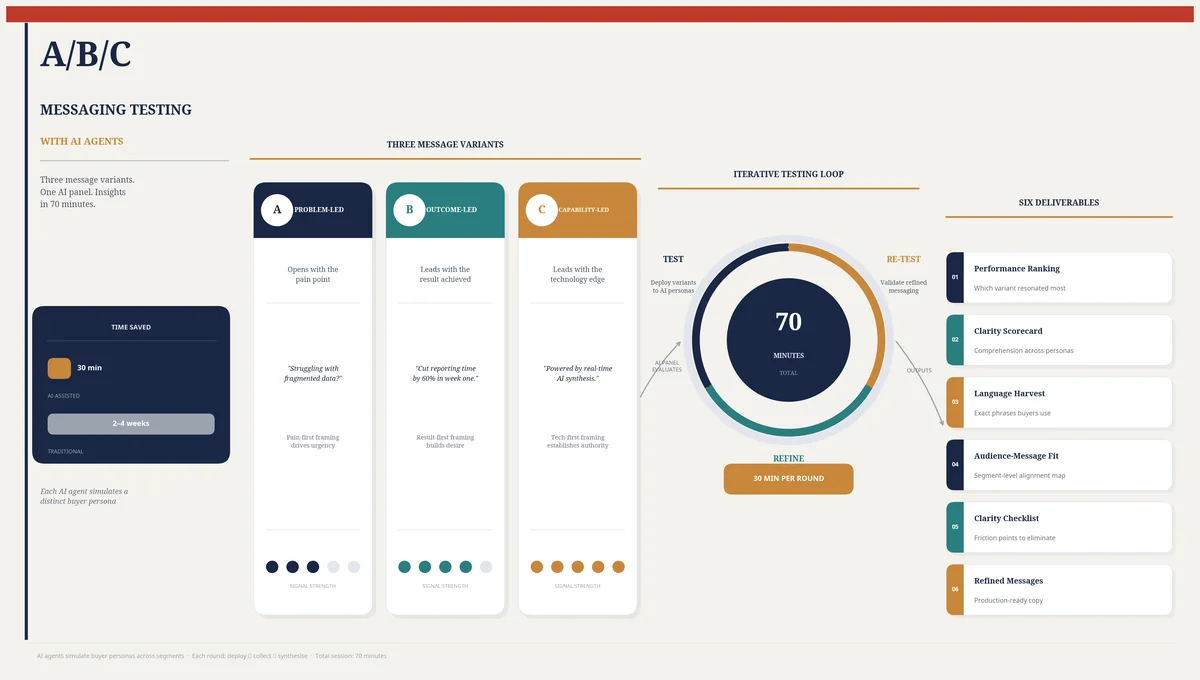
This article describes a method for testing messaging with the same discipline you apply to positioning. Using Ditto, a synthetic market research platform with over 300,000 AI personas, and Claude Code, Anthropic's agentic development environment, you can test three messaging variants against your target audience in thirty minutes, refine the winner, and re-test with fresh personas in another thirty. Seventy minutes from first draft to validated messaging. The same process through Wynter takes three to five days and costs $300 to $600 per test. Through customer interviews, two to four weeks. Through Qualtrics surveys, $2,000 to $10,000 and a month of your life. And live A/B testing only works if you have traffic, which means you need to have already launched, which means you are testing messaging with real revenue at stake.
The Messaging Gap
The fundamental problem with traditional message testing is iteration speed. Messaging is not a problem you solve once. It is a problem you solve repeatedly, because the right message changes as your market evolves, your competitors respond, and your product matures. A tagline that worked brilliantly at launch may feel generic twelve months later when three competitors have adopted similar language.
The Product Marketing Alliance's State of Product Marketing report consistently shows that messaging and positioning are the top two responsibilities cited by PMMs. And yet when you ask how messaging decisions are made, the answers tend to cluster around committee preference, HiPPO dynamics (the Highest Paid Person's Opinion), and the copywriter's instinct. These are not unreasonable inputs. They are simply not enough.
Consider the economics. Wynter's B2B message testing panels are excellent but narrow: you get a specific audience panel's feedback on one piece of copy, and results take three to five business days. If you want to test three variants, that is three separate tests, three rounds of waiting, and $900 to $1,800. If the first round of feedback suggests a fourth direction, you are looking at another week and another $300 to $600. The quality is high. The velocity is not.
Customer interviews provide richer qualitative data but require recruitment, scheduling, and synthesis. Teresa Torres's continuous discovery framework recommends weekly interviews, which is admirable, but few teams sustain it, and interview data is notoriously difficult to aggregate into clear messaging decisions. Ten customers will give you ten different reactions, and the patterns only emerge after careful analysis that most teams lack the time or training to perform.
The result is predictable. Messaging is tested less rigorously than positioning, updated less frequently than it should be, and evaluated primarily through lagging indicators (conversion rates, win rates) rather than leading ones (clarity, resonance, differentiation). By the time you discover that your messaging is underperforming, you have already lost months of pipeline to a problem that was, in principle, testable from the start.
Three Messaging Framings
Before you test, you need something worth testing. And the most common mistake in message testing is testing variations that are merely cosmetic: the same idea with different adjectives. The test results are inconclusive because the inputs were insufficiently different.
A more productive approach is to test three genuinely distinct framings of the same positioning. The positioning stays constant. The framing changes. Here are the three that matter most:
Problem-Led Messaging
Lead with the pain. The customer's world is broken in a specific, recognisable way, and your product fixes it. This framing works best when the problem is acute, widely felt, and poorly solved by existing alternatives. It assumes the customer is already aware of their pain and is actively seeking relief.
Example: "Your pricing page is losing you 30% of qualified prospects. They land, they look, they leave. Not because your product is wrong, but because your pricing is confusing. Fix it in 30 minutes with validated customer research."
Problem-led messaging has velocity. It creates urgency. It also risks sounding negative, and it fails when the customer does not yet recognise the problem you are describing. If you are creating a new category, the problem framing can feel like a solution in search of a disease.
Outcome-Led Messaging
Lead with the result. Skip the problem entirely and describe the world after the customer has used your product. This framing works best when the outcome is aspirational and the path from current state to desired state is unclear. It sells the destination, not the journey.
Example: "Know exactly what your customers want to hear, before you say it. Test messaging with 300,000 AI personas and launch with confidence."
Outcome-led messaging feels expansive and optimistic. It works well for products that enable transformation rather than fixing a specific pain. Its weakness is vagueness: if the outcome is not specific enough, the message reads like aspiration without substance. "Unlock your potential" is outcome-led messaging. It is also entirely meaningless.
Capability-Led Messaging
Lead with the mechanism. How the product works is the message. This framing is effective when the mechanism itself is novel, differentiating, or interesting enough to carry the narrative. It assumes the customer will connect the capability to their own problem or desired outcome.
Example: "300,000 AI personas. Seven questions. Thirty minutes. Three messaging variants tested against real demographic profiles, with language-level analysis of what resonated and what fell flat."
Capability-led messaging appeals to evaluators, technical buyers, and anyone who distrusts marketing promises. Its weakness is that it requires the audience to do the imaginative work of connecting the capability to their context. Not everyone will bother.
The point is not that one framing is superior. It is that the same positioning produces three meaningfully different messages, and without testing, you are guessing which one your specific audience prefers. In my experience, the answer is rarely obvious. I have seen problem-led messaging win overwhelmingly in markets where I expected outcome-led to dominate, and vice versa. The only way to know is to ask.
The Seven-Question Messaging Study
The study design tests three messaging variants through seven questions, each revealing a different dimension of how the message lands. The Claude Code guide automates the entire sequence through Ditto's API, but understanding what each question measures is essential for interpreting the results.
Claude Code begins by taking your three messaging variants (problem-led, outcome-led, capability-led, or whichever three framings you provide) and customising the study for your target audience. It creates a Ditto research group of ten personas matching your buyer profile: job titles, industries, company sizes, geographies. Then it runs the seven questions sequentially.
Question 1: First Impression of Message A. "Read this message. What is your first reaction? What do you think this product does? Who do you think it is for?"
This question is more revealing than it appears. You are not asking whether the persona likes the message. You are asking whether they understand it. The gap between what you intended the message to communicate and what the persona actually understood is the clarity gap. If five out of ten personas cannot accurately describe what the product does after reading your headline and subhead, you have a clarity problem that no amount of creative refinement will fix. You need to rewrite, not refine.
Question 2: Comparison with Message B. "Now read this second message for the same product. How does it compare to the first? Which feels more relevant to your needs? Which is clearer?"
Direct comparison forces a choice, and the reasoning behind the choice is the data. A persona who says "Message B is clearer because it tells me exactly what I will get" is providing a specificity signal. A persona who says "Message A feels more urgent" is providing an emotional resonance signal. The aggregate pattern across ten personas tells you whether your audience makes messaging decisions on clarity, emotion, specificity, or novelty. This shapes not just which message wins but how you refine the winner.
Question 3: Three-Way Choice. "Here is a third message. Now considering all three, which one would most likely make you want to learn more? Rank them. Why?"
This is the headline test. When presented with three options, personas must articulate their preference hierarchy and justify it. The rankings produce a clear winner or reveal a split audience. A six-three-one split is a strong signal. A four-four-two split suggests your audience is segmented and may need different messaging for different segments, a finding that is itself valuable.
Question 4: Clarity Gaps. "After reading all three messages, what questions do you still have? What is unclear or missing?"
This question catches what the preference rankings miss: the gaps. Personas may prefer Message A but still have fundamental questions that Message A fails to answer. The most common clarity gaps are: "How does it actually work?" (mechanism gap), "How is this different from what I already use?" (differentiation gap), and "What does this cost?" (commitment gap). Each gap maps directly to a messaging fix. If seven personas ask how it works, your messaging needs a mechanism sentence. If six ask how it differs from competitors, you need a sharper differentiation claim.
Question 5: Click-Through Expectations. "If you clicked on this message, what would you expect to find on the next page? What would make you stay? What would make you leave immediately?"
This question tests whether the messaging sets accurate expectations. Messaging that overpromises creates a click that bounces. Messaging that underpromises fails to create the click at all. The ideal message sets expectations that the landing page can exceed. When personas describe what they expect to find, they are writing your landing page brief for you. And when they describe what would make them leave immediately, they are flagging the trust-breakers: generic content, walls of text, aggressive lead capture forms, or a disconnect between the promise and the product.
Question 6: Language Harvest. "Which specific words or phrases from the messages stuck with you? Which felt forced, jargony, or off-putting? If you were describing this product to a colleague, how would you say it in your own words?"
This is, in my view, the most valuable question in the study. It produces three things: the words that resonated (use them), the words that repelled (kill them), and the words the customer would actually use to describe your product (steal them). That last category is gold. When a persona says "it's basically a way to test your marketing copy with fake people before you waste money on real ads," they have just handed you a homepage headline that is more honest, more vivid, and more persuasive than anything your copywriting team produced. I will return to this in detail later.
Question 7: Problem Urgency. "How urgently do you need a solution for this? Is this a problem you are actively trying to solve right now, or more of a nice-to-have?"
This final question calibrates urgency and intent. If eight of ten personas describe the problem as urgent, your messaging can be aggressive and action-oriented. If most describe it as a nice-to-have, your messaging needs to create urgency rather than assume it. The split also tells you where the product sits in the buyer's priority stack: a top-three problem demands different messaging than a "we'll get to it eventually" problem. Messaging that assumes urgency where none exists reads as tone-deaf. Messaging that fails to capitalise on existing urgency reads as passive.
The Iterative Loop: Test, Refine, Re-Test
If the study design is the engine, the iteration loop is what makes it genuinely powerful. Here is the sequence:
Round 1 (approximately thirty minutes). Run the seven-question study with your three initial messaging variants against ten personas. Analyse the results. Identify the winning variant, the strongest language, the clarity gaps, and the audience signals.
Refinement (approximately ten minutes). Take the winning variant and improve it. Close the clarity gaps identified in Question 4. Incorporate the resonant language from Question 6. Address the expectation mismatches from Question 5. You now have a refined version of the winner, plus potentially a new variant that combines the best elements of all three.
Round 2 (approximately thirty minutes). Run the study again with the refined variant and one or two alternatives, against a fresh set of ten personas. Fresh personas matter: you need to avoid confirmation bias from the first group. If the same variant wins both rounds with different personas, you have convergence. If a different variant wins, you have learned that the refinement changed the dynamics and need to investigate why.
The total elapsed time is seventy minutes: thirty, ten, thirty. For context, scheduling and conducting three customer interviews takes a minimum of two weeks, and most messaging workshops run for half a day without producing testable outputs. Seventy minutes is not just faster. It is a fundamentally different relationship with message testing. It becomes something you do routinely, not something you do once a year when the website gets redesigned.
I should note that the thirty-minute figure is not marketing fiction. Ditto's personas generate qualitative responses asynchronously, and Claude Code handles the orchestration: creating the research group, formatting the questions, polling for responses, and synthesising the results. The human work is defining the three variants and interpreting the findings. The machinery handles everything else.
Six Deliverables
A completed messaging study produces seventy qualitative responses across seven questions from ten personas. Claude Code analyses these and generates six structured outputs:
Message Performance Ranking. Which variant won, by what margin, and why. Includes the vote split across personas, the most common reasons for preference, and the specific dimensions on which the winner outperformed (clarity, relevance, emotional resonance, differentiation).
Clarity Scorecard. For each messaging variant, a summary of what was understood correctly, what was misunderstood, and what was missed entirely. Maps each clarity gap to a specific fix. If seven personas could not explain what the product does after reading Message A, the scorecard says so and recommends a mechanism sentence.
Language Harvest. The specific words, phrases, and framings that resonated, repelled, or were generated spontaneously by personas. Organised into three categories: 'Keep' (language that worked), 'Kill' (language that fell flat or confused), and 'Steal' (the customer's own words for what your product does).
Audience-Message Fit Matrix. If personas with different demographic or psychographic profiles preferred different variants, this matrix maps the variation. A technical buyer who preferred the capability-led message and a business buyer who preferred the outcome-led message is a segmentation finding with direct implications for how you tailor messaging by channel and audience.
Clarity Checklist. A prioritised list of specific changes to make: add a mechanism sentence, remove the jargon term that confused four personas, replace the abstract benefit with the concrete outcome that three personas spontaneously described. Each item is grounded in a specific study finding.
Refined Message Set. The optimised version of the winning variant, incorporating the strongest language from the harvest, the clarity fixes from the checklist, and the expectation alignment from Question 5. This is not a draft. It is a tested, refined, evidence-based message ready for deployment.
The Language Harvest: The Most Undervalued Output
I want to dwell on this because it is the output that most consistently surprises teams. The language harvest is not a summary. It is a collection of exact phrases that emerged naturally from persona responses, and these phrases have a quality that internally generated copy almost never achieves: they sound like customers.
When a persona says "I like that it lets me test ideas before I commit budget to them," that phrase, test ideas before I commit budget, is a headline. It is concrete, it implies risk mitigation, and it uses the language of someone who actually has budget constraints. Compare it to the internally generated alternative: "Validate your messaging strategy with AI-powered consumer insights." Both describe the same product. One sounds like a person. The other sounds like a LinkedIn post.
The harvest captures three categories of language:
Resonant language. Phrases from your messaging that personas explicitly praised or repeated back. These have survived the comprehension test and should be preserved in the final copy.
Rejected language. Words and phrases that personas flagged as confusing, jargony, or off-putting. "AI-powered" was consistently rejected in one study I ran because personas associated it with chatbots, not research. We replaced it with "300,000 synthetic consumers" and the clarity scores improved dramatically.
Spontaneous language. The words personas used when asked to describe the product in their own terms. These are frequently more vivid, more specific, and more honest than anything the marketing team wrote. One persona described a project management tool as "the thing that stops my team from pretending they have read my emails." That is not a tagline you would write in a workshop. It is a tagline that works.
The practical applications are immediate. Resonant phrases become headlines and ad copy. Rejected words get removed from the entire marketing stack, not just the tested message. Spontaneous language becomes email subject lines, social proof quotes, and sales talk tracks. One study's language harvest can supply a month of content variations. It is, per unit of effort, the highest-yield output in the entire messaging workflow.
Cross-Segment Testing
The basic study tests one message set against one audience. The advanced version asks a harder question: does the same messaging work across all your target segments, or do you need segment-specific variants?
Claude Code orchestrates this by running the same seven-question study against multiple Ditto research groups in parallel. For a B2B SaaS product, you might test against:
Group 1: Product managers (age 28 to 40, employed in technology). Care about user research, iteration speed, and integration with existing tools.
Group 2: Marketing directors (age 35 to 50, employed). Care about campaign performance, brand consistency, and ROI justification.
Group 3: Founders and CEOs (age 30 to 55, employed). Care about competitive advantage, speed to market, and cost efficiency.
Same three messages. Three audiences. The results frequently diverge. Product managers may prefer the capability-led variant because they want to understand the mechanism. Marketing directors may prefer the outcome-led variant because they need to justify the tool to their VP. Founders may prefer the problem-led variant because they feel the pain most acutely.
When the results diverge, you have a decision to make. Do you pick the message that performs best on average across all segments? Or do you create segment-specific messaging, deploying the problem-led variant in founder-targeted ads and the capability-led variant in product manager-targeted content? The cross-segment study does not make this decision for you. It gives you the data to make it intelligently rather than by assumption.
This has implications for channel strategy. Your homepage must serve all segments and needs the broadest-performing message. Your email nurture sequences can be segmented. Your paid ads should use the segment-specific winner. The Audience-Message Fit Matrix from the deliverables makes these allocation decisions straightforward.
Where Messaging Fits in the PMM Stack
Messaging sits in a specific position in the product marketing workflow, and that position matters because the inputs from upstream work directly determine the quality of your messaging variants.
Positioning validation establishes your competitive alternatives, unique attributes, and best-fit customers. Without validated positioning, you are testing messages built on assumptions. Messaging testing does not replace positioning work. It translates positioning into customer-facing language.
Messaging testing (this article) validates how to communicate your value. Which framing resonates? Which language sticks? Where are the clarity gaps? This step produces the specific words and structures your marketing will use.
Pricing research validates what the market will pay and how it wants to buy. Your pricing page is a messaging surface: the tier names, the feature comparison copy, the CTA language all benefit from the language harvest produced in the messaging study.
Competitive intelligence provides the competitive context. Knowing how competitors message their products helps you identify differentiation opportunities and avoid inadvertently echoing the language of a rival. If every competitor leads with "AI-powered," your messaging study may reveal that a different framing cuts through the noise.
Content and sales enablement sit downstream. The validated messaging becomes the source material for website copy, email campaigns, ad creative, pitch decks, and sales talk tracks. Every downstream asset is stronger when it is built on tested messaging rather than workshop consensus.
With Ditto and Claude Code, the complete sequence from positioning through validated messaging can be completed in under two hours. Positioning validation takes roughly thirty minutes. Two rounds of message testing take seventy minutes. The strategic thinking and variant creation between stages takes the rest. What traditionally occupies a quarter of calendar time becomes an intensive afternoon.
Limitations and Where Traditional Methods Still Win
Synthetic message testing produces qualitative directional data. It tells you which framing resonates, which language sticks, and where clarity breaks down. It does not produce the statistical precision of a 500-respondent Qualtrics panel with conjoint analysis.
Three specific limitations are worth stating plainly:
Tone of voice nuance. Ditto's personas respond to meaning and framing, not to the subtle tonal differences between, say, a warm conversational tone and a dry authoritative tone using the same words. If your messaging variants differ primarily in voice rather than substance, the study will struggle to differentiate them. Test substance first, then refine tone through other methods.
Visual and design context. Messaging never exists in isolation. The same words perform differently in a hero banner with a product screenshot than in a plain-text email. Ditto tests the language itself, not the layout, typography, or visual context in which it will appear. Pair messaging studies with visual A/B tests when the design context matters.
Behavioural validation. A persona that says "I would click on this" is expressing intent, not demonstrating behaviour. The correlation between stated intent and actual behaviour in synthetic research is strong, validated by studies at Harvard, Cambridge, Stanford, and Oxford, and confirmed by EY Americas at ninety-five percent. But real-world A/B tests remain the definitive confirmation. Use synthetic studies to narrow the field from infinite possibilities to two or three strong candidates, then validate the winner with live traffic.
The honest recommendation is this: use Ditto and Claude Code for the exploration phase, where speed and iteration matter most, and reserve your A/B testing budget for the confirmation phase, where statistical precision matters most. Most teams do it the other way round, exploring slowly through committee debate and then testing too late to change course. Reverse the order and you will be surprised how much more confidently you launch.
Getting Started
If you have a positioning document (or even a rough idea of your product's unique value), you can test messaging today. Write three variants: one leading with the problem, one leading with the outcome, one leading with the capability. They do not need to be polished. In fact, rough variants often produce more useful data than refined ones, because the feedback is about the framing rather than the wordsmithing.
Ditto provides the always-available customer panel. Claude Code handles the orchestration: customising the seven questions, creating the research group, running the study, analysing seventy responses, and producing the six deliverables. The messaging testing guide walks through the full workflow, including the cross-segment extension and the iterative refinement loop.
Positioning is what you believe. Messaging is what your customer hears. The gap between the two is measurable, and closing it takes seventy minutes.
The AI Agents for Product Marketing Series
Part 1: How to Validate Product Positioning with AI Agents | Claude Code Guide
Part 2: Competitive Intelligence with AI Agents | Claude Code Guide
Part 3: How to Research Pricing with AI Agents | Claude Code Guide
Part 4: How to Test Product Messaging with AI Agents (this article) | Claude Code Guide
Part 5: How to Run Voice of Customer Research with AI Agents | Claude Code Guide
The Claude Code and Ditto for Product Marketing Series
This article is part of a series on using Claude Code and Ditto for product marketing. Each article explains a specific workflow; each has a corresponding Claude Code technical guide for hands-on implementation.
Part 1: How to Validate Product Positioning with Claude Code and Ditto | Claude Code Guide
Part 2: How to Build Competitive Battlecards with Claude Code and Ditto | Claude Code Guide
Part 3: How to Research Pricing with Claude Code and Ditto | Claude Code Guide
Part 4: How to Test Product Messaging with Claude Code and Ditto (this article) | Claude Code Guide
Part 5: How to Run Voice of Customer Research with Claude Code and Ditto | Claude Code Guide
Part 6: How to Segment Customers with Claude Code and Ditto | Claude Code Guide
Part 7: How to Validate GTM Strategy with Claude Code and Ditto | Claude Code Guide