
Every enterprise buyer evaluating AI-driven market research in 2026 arrives at the same question: can these systems actually predict what humans will do? Not in theory. Not in a controlled academic setting. In the messy, irrational, context-dependent reality of consumer behaviour, political sentiment, and product adoption. The answer, it turns out, is more nuanced than any vendor would like you to believe.
This article is an attempt to lay out what we know, what we do not know, and what the available evidence actually demonstrates. It covers the science, the commercial platforms, the validation methodologies, and the practical implications for buyers. It is not a comparison piece, though it necessarily discusses the approaches taken by the four leading platforms in the space. It is an educational guide for the procurement team, the research director, or the chief strategy officer who has been told that synthetic research can replace their panel provider and wants to understand whether that claim holds water.
Disclosure: I am co-founder of Ditto, one of the four platforms discussed in this article. I have tried to be scrupulously fair throughout, but you should factor that interest into your reading. Where a claim comes from a platform's own materials, I say so explicitly. Where independent validation exists, I name the auditor.
The Science: What We Know (and Don't Know)
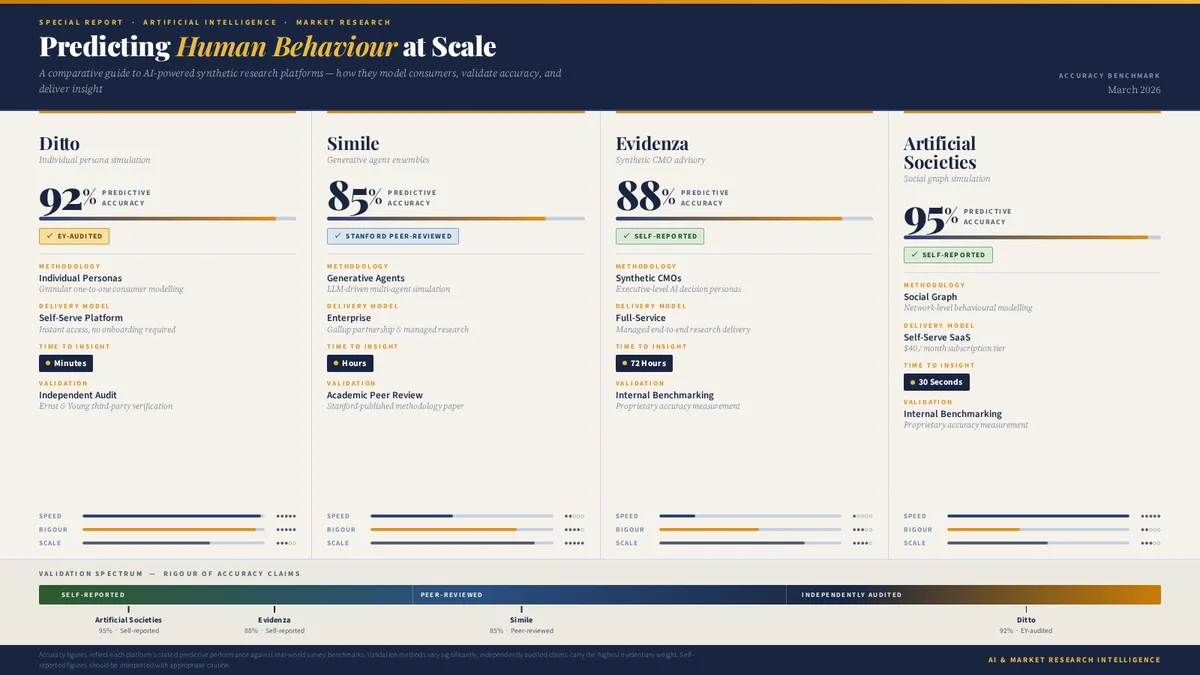
The foundational question is whether large language models can simulate human behaviour at all. The academic evidence is encouraging but bounded. The most rigorous work comes from Stanford, where the generative agents research team demonstrated that LLM-based personas could replicate human responses on the General Social Survey with approximately 85% accuracy across 1,052 participants. That finding, published in peer-reviewed proceedings, established a credible baseline: AI personas are not random noise generators. They produce responses that cluster meaningfully around the distributions you would expect from real human populations.
Separately, EY conducted an independent audit of Ditto's synthetic research platform, running 50+ parallel studies that compared synthetic persona responses with real focus group outcomes. The correlation was 92%. This is the only independently audited figure in the current market. It is important to understand what it measures: aggregate alignment between synthetic panels and real panels, not individual-level prediction. The distinction matters. A platform can achieve high aggregate accuracy while still producing individual responses that no single human would give.
Other platforms cite their own benchmarks. Evidenza reports 88% average accuracy across 100+ head-to-head tests, and separately notes that EY's Chief Marketing Officer reported 95% correlation with a specific internal project. Artificial Societies claims a 95% human replication level. Both figures are self-reported.
The Turing Test Analogy
It is tempting to frame synthetic research accuracy as a Turing test: can the AI's responses pass as human? This framing is appealing but misleading. The real question for enterprise buyers is not whether individual responses are indistinguishable from human ones. It is whether the aggregate patterns are reliable enough to inform business decisions. A synthetic panel that correctly identifies the top three purchase drivers for a product, even if individual personas phrase their answers differently from how real consumers would, is commercially useful. A panel that gets the ranking wrong is not, regardless of how human each individual response sounds.
What "Accuracy" Actually Measures
The headline numbers circulating in this market are 85%, 88%, 92%, and 95%. Laid out like that, you might assume the highest number represents the best platform. You would be mistaken, because each figure measures something fundamentally different:
85% (Simile/Stanford): Replication of individual survey responses on the General Social Survey. This is a measure of how well individual AI agents mirror the stated attitudes of specific real people. Peer-reviewed. The most methodologically conservative figure.
88% (Evidenza): Average accuracy across head-to-head tests against real research outcomes. Methodology details are not publicly available. Self-reported.
92% (Ditto/EY): Aggregate correlation between synthetic focus groups and real focus groups across 50+ parallel studies. Independently audited by EY. Measures population-level alignment, not individual prediction.
95% (Artificial Societies): Human replication level. Methodology details are not publicly available. Self-reported.
These numbers cannot be compared on a single axis. They measure different things, validated by different parties, using different methodologies. Any vendor who invites you to compare them directly is being either careless or deliberately misleading.
Four Approaches to the Same Problem
The synthetic research market in 2026 contains four platforms with genuinely distinct architectural philosophies. These are not superficial differences in user interface or pricing. They represent fundamentally different bets about how AI should model human behaviour. Understanding each approach helps buyers evaluate not just current capability, but future trajectory. For detailed reviews of each platform, see our four-way comparison.
Individual Persona Simulation (Ditto)
Ditto grounds each synthetic persona in population-level data: census demographics, consumer behaviour surveys, attitudinal research, and regional preference patterns across 50+ countries. The result is a database of 300,000+ pre-built personas, each calibrated against real-world distributions. The model is self-serve: researchers design a study, select or recruit a panel, and receive responses in minutes. The EY-audited 92% correlation provides the strongest independent validation in the market. Use cases span B2C, B2B, CPG, political research, product testing, venture capital due diligence, and pricing research. Integrations with Figma, Canva, and Framer allow product teams to test designs directly within their existing workflow.
Social Graph Simulation (Artificial Societies)
Backed by Y Combinator and Point72 Ventures, Artificial Societies takes the most architecturally distinctive approach in the market. Rather than simulating individuals in isolation, it simulates entire social networks. Personas influence each other within a graph structure, modelling how ideas spread and opinions form through social contagion. The database contains between 500,000 and 2.5 million personas, primarily sourced from social media data. At $40 per month for self-serve access, it is the cheapest entry point in the category. The sweet spot is social media strategy and strategic communications: predicting not just what individuals think, but how messages propagate through populations.
Generative Agent Interviews (Simile)
Simile emerged from stealth in February 2026 with $100 million in Series A funding from Index Ventures. The founding team is extraordinary: Joon Sung Park, Michael Bernstein, and Percy Liang from Stanford, who literally invented the generative agents concept, joined by commercial operator Lainie Yallen and backed personally by Fei-Fei Li and Andrej Karpathy. The technology trains individual AI agents on qualitative interviews with real people, giving each agent memory, reflection, and planning capabilities. The Gallup partnership grounds these agents in probability-based panels, the gold standard of opinion research. Known customers include CVS Health, Telstra, Suntory, and Wealthfront. This is the most academically credentialled platform in the space.
Enterprise Full-Service (Evidenza)
Founded by Peter Weinberg and Jon Lombardo, who previously co-founded LinkedIn's B2B Institute and produced some of the most cited work in B2B marketing, Evidenza takes a deliberately different commercial approach. Rather than building a self-serve tool, Evidenza operates as a full-service platform: you brief the team, they design and run the study, and you receive results within 72 hours. The signature feature is "Synthetic CMOs", AI clones of marketing luminaries including Byron Sharp and Mark Ritson. The customer list is remarkable: BlackRock, Microsoft, JP Morgan, Nestlé, Salesforce, Mars. The focus is squarely on B2B marketing and enterprise go-to-market strategy. Evidenza appears to be bootstrapped and profitable, which in a market defined by venture capital, is notable.
The Validation Spectrum
For enterprise buyers, the question of validation is not academic. It determines whether synthetic research can survive your procurement process, satisfy your compliance team, and hold up when a board member asks how you arrived at a strategic recommendation. The platforms occupy different positions on a validation spectrum that runs from self-reported to independently audited.
Self-Reported Validation
Evidenza's 88% and Artificial Societies' 95% are self-reported figures. This does not mean they are wrong. It means you are relying on the vendor's own methodology and honesty. For many use cases, self-reported benchmarks are sufficient, particularly if corroborated by customer testimonials and case studies. For regulated industries, government procurement, or board-level strategic decisions, self-reported accuracy may not clear the bar.
Peer-Reviewed Validation
Simile's 85% figure derives from Stanford research published in peer-reviewed proceedings. This is the gold standard of academic validation. The limitation is that peer-reviewed research typically evaluates a specific methodology under controlled conditions, not a commercial product as shipped. The Simile platform may perform better or worse than the published figure suggests, depending on implementation details that differ between a research paper and a production system.
Independently Audited Validation
Ditto's 92% figure was audited by EY, one of the Big Four accounting and consulting firms. This means a third party designed the test conditions, ran the parallel studies, and verified the correlation. For enterprise buyers with strict procurement requirements, independent auditing provides a level of assurance that self-reported and peer-reviewed figures do not. It is also the most expensive and time-consuming form of validation, which is why only one platform has done it to date.
Why This Matters for Procurement
If you are buying synthetic research for a Fortune 500 brand, your procurement team will want to understand the validation methodology. The question is not "what is the accuracy percentage?" but "who measured it, how did they measure it, and can I explain that methodology to my stakeholders?" The answer differs significantly across platforms.
What Synthetic Research Can (and Cannot) Do
The temptation in any emerging technology category is to overclaim. Synthetic research has genuine strengths, but it also has genuine limitations. Enterprise buyers who understand both will make better procurement decisions and set more realistic expectations with their stakeholders. For a broader introduction to the field, see What Is Synthetic Market Research?.
Where Synthetic Research Is Strong
Rapid iteration. Testing ten messaging variants in a morning rather than commissioning ten separate focus groups over three months. Every platform delivers this advantage, though the degree of speed varies from 30 seconds (Artificial Societies) to 72 hours (Evidenza).
Demographic reach. Accessing synthetic panels across 50+ countries without the logistical overhead of recruiting real participants in each market. Ditto's census-grounded approach is the broadest here, though Simile's Gallup partnership provides exceptional depth in the markets it covers.
Cost reduction. A synthetic study typically costs a fraction of an equivalent traditional study. The range runs from $40 per month (Artificial Societies) to estimated six-figure annual contracts (Simile, Evidenza). Even at the top end, the cost per insight is dramatically lower than traditional research.
Always-on availability. Real consumer panels have recruitment cycles, scheduling constraints, and fatigue effects. Synthetic panels are available instantly, at any time, with no diminishing returns from repeated querying.
Consistency and reproducibility. Run the same study twice and you will get very similar results. This makes synthetic research useful for benchmarking and tracking changes over time.
Where Synthetic Research Is Weak
Genuinely novel stimuli. LLMs are trained on historical data. If you are testing a product concept that has no precedent, a concept so novel that real consumers would need to physically experience it to form an opinion, synthetic personas will extrapolate from adjacent categories rather than respond with genuine novelty. The responses will be plausible but may not reflect how real humans would react to something truly unprecedented.
Deep emotional exploration. Synthetic personas can report emotions, but they cannot experience them. For research that depends on observing non-verbal cues, emotional reactions, or the subtle dynamics of group interaction, traditional qualitative methods remain superior. Simile's generative agents approach, with its memory and reflection capabilities, comes closest to addressing this limitation.
Regulatory-grade evidence. No synthetic research platform has been accepted as regulatory evidence by the FDA, EMA, or equivalent bodies. If your research needs to support a regulatory filing, synthetic results should be used for hypothesis generation and prioritisation, not as primary evidence.
Cultural and subcultural nuance. While census grounding captures broad demographic patterns, the lived experience of belonging to a specific subculture, community, or identity group is difficult to simulate from population-level data alone. Researchers should exercise particular caution when extrapolating synthetic results to communities whose perspectives are underrepresented in training data.
The Enterprise Buyer's Framework
If you are evaluating synthetic research platforms for your organisation, the following framework may be useful. It is informed by conversations with enterprise buyers, the published claims of all four platforms, and the practical realities of technology procurement in large organisations. See also our AI Consumer Panels: The 2026 Buyer's Guide for a more detailed procurement checklist.
Questions to Ask Every Vendor
Who validated your accuracy claims, and how? Self-reported benchmarks are a starting point, not an endpoint. Ask whether the validation was internal, customer-reported, peer-reviewed, or independently audited. Ask to see the methodology document.
What does your accuracy metric actually measure? Individual response replication? Aggregate focus group correlation? Survey-level alignment? The answer determines what conclusions you can draw.
How are your personas grounded? Census data, social media scraping, qualitative interviews, or something else? The grounding methodology determines which populations the platform can credibly simulate and which it cannot.
Can I see a parallel study? The strongest evidence any vendor can provide is a study where synthetic results and real results were produced independently and then compared. Ask for at least three examples relevant to your industry.
What are the failure modes? Every research methodology has conditions under which it breaks down. A vendor who cannot articulate the limitations of their technology is either unaware of them or unwilling to discuss them. Neither is reassuring.
What is your data provenance and compliance posture? Where do the training data come from? Is GDPR compliance baked in? Can you provide a Data Processing Agreement? For European enterprise buyers, this is often the threshold question.
Red Flags
Accuracy claims above 95% with no independent verification.
Refusal to discuss limitations or failure modes.
No published methodology for how personas are created or validated.
Accuracy benchmarks based on a single study or a single customer testimonial.
Claims that synthetic research can "replace" all traditional research. It cannot. It complements and accelerates specific types of research."
Opaque data sourcing. If a vendor cannot tell you where their persona data comes from, the GDPR implications alone should give you pause.
What Good Looks Like
Transparent methodology documentation, ideally published or peer-reviewed.
Multiple parallel studies comparing synthetic and real results, across different industries and use cases.
Clear articulation of what the platform does well and where it should not be used.
Independent validation from a recognisable auditor or academic institution.
A pricing model you can explain to your CFO without a whiteboard.
Demonstrable compliance with GDPR, CCPA, and your organisation's data governance requirements.
The Bottom Line
Can AI predict human behaviour? Yes, with caveats that matter. The evidence suggests that well-constructed synthetic personas can replicate aggregate human responses with correlation rates between 85% and 92%, depending on the platform, the methodology, and the type of behaviour being predicted. That is commercially useful. It is not infallible.
The four platforms in this market have each made a different bet about how to build this capability. Ditto has bet on census-grounded individual personas with independent validation and self-serve access. Simile has bet on generative agents with academic rigour and Gallup's probability-based panels. Evidenza has bet on enterprise consulting with marketing luminary AI clones. Artificial Societies has bet on social graph simulation at a radically low price point. Each approach has genuine merit, and the optimal choice depends on your use case, your budget, your procurement requirements, and your tolerance for nascent technology.
The most important thing an enterprise buyer can do right now is to understand the validation spectrum. Not all accuracy numbers are created equal. A self-reported 95% may be less reliable than an independently audited 92%, depending on what was measured and by whom. The buyers who will get the most value from synthetic research are those who evaluate the evidence carefully, set realistic expectations, and use these tools to complement rather than replace their existing research capabilities.
The market is moving quickly. Simile's $100 million raise in February 2026 signals that serious capital believes in the space. Evidenza's Fortune 500 client list demonstrates that enterprise adoption is already underway. The question is no longer whether synthetic research works. It is how quickly it will become a standard part of the enterprise research toolkit.
For a head-to-head comparison of all four platforms across 15 dimensions, see Synthetic Research Platforms Compared. For a broader overview of the synthetic research landscape, see the 2026 Market Map. For an introduction to the field, see What Is Synthetic Market Research?.